First of all while many people talk about Promoted Property, the official term is Promoted Field, as defined in the MSDN documentation and also visible in Visual Studio’s BizTalk Schema Editor. I will nevertheless keep using the term most people are familiar with but I will consider both terms as synonyms.
Part 1 & 2 is a tutorial on how to create promoted properties and distinguished fields through the Schema Editor and the BizTalk’s API while part 3 is discussing about performance and differences between Promoted Properties and Distinguished Fields. You might only be interested in the 3rd part of this article if you already are a seasoned BizTalk developer.
1. Promoted Properties (Promoted Fields)
1.1 What are Promoted Properties?
Promoted Properties are Message Context Properties that are flagged as promoted; being promoted it allows the Message Engine to route messages based on their value, and being in the message context allows doing so without having to look at the message payload (which would be an expensive operation). Promoted Properties are the most common way to enable content-based routing. They are available to the pipelines, adapters, Message Bus and orchestrations.
Promoted Fields (= Promoted Properties) are PROMOTED in the message context by the receive pipeline when a message is received on a port. It is usually the job of the disassembler pipeline component such as the XML and Flat File disassembler but any custom pipeline component can also do it.
1.2 How to promote properties?
As stated in a previous post I wrote, BizTalk Messaging Architecture, message context properties are defined within a property schema and so all promoted properties must be defined in a custom property schema.
The action of promoting a message element to a promoted property creates a message context property that will contain the message element value and flags it as promoted so that it is available for routing.
There are 2 ways to promote a message element:
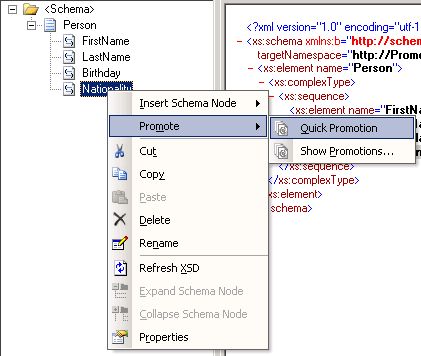
1. Quick promotion
Quick promotion is the simplest way to create a promoted property. Simply right click on the element’s node and choose Quick Promotion (see Fig 1.1). When choosing this option, Visual Studio will create a property schema called PropertySchema.xsd and add in the message’s schema a reference to the generated property schema.
Each property promoted this way will create a corresponding element in the property schema with the same name and type as defined in the message’s schema.
This means that when using quick promotion, the promoted property element name will always be the same as the message’s element name. If you have several elements with the same name, you might want to use manual promotion instead to avoid confusion or avoid having a property value overridden.
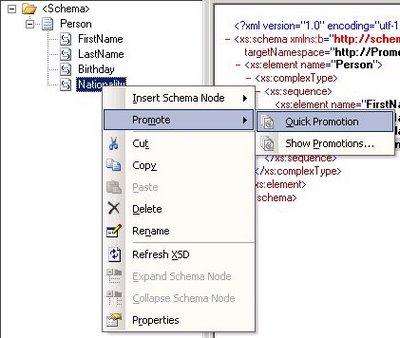 Fig. 1.1 Quick Promotion
Fig. 1.1 Quick Promotion
2. Manual Promotion
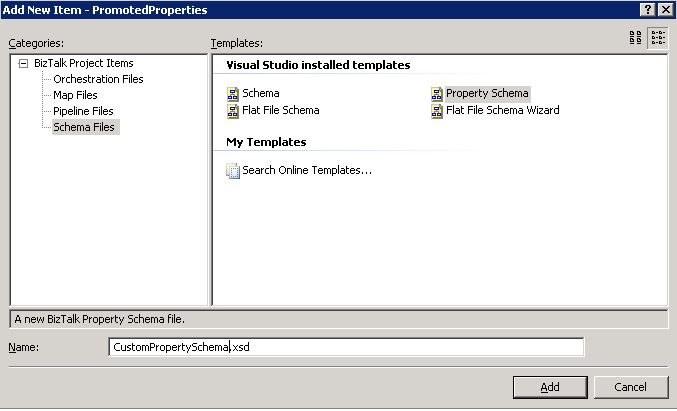
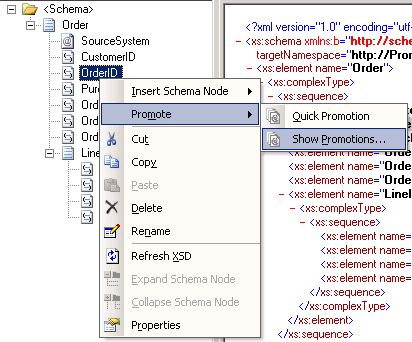
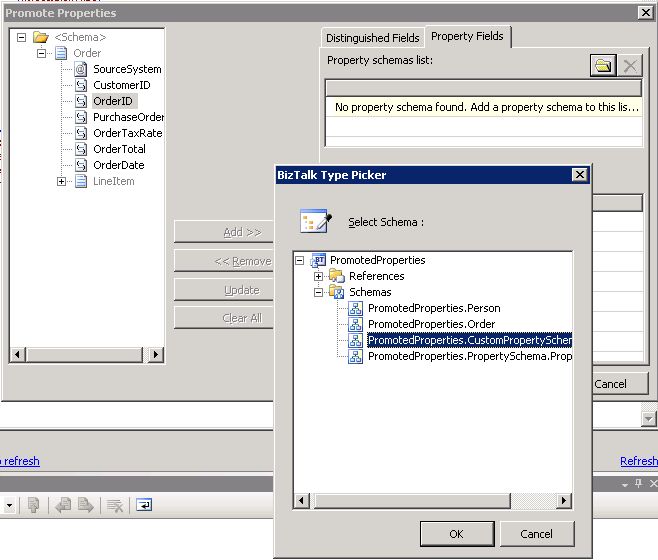
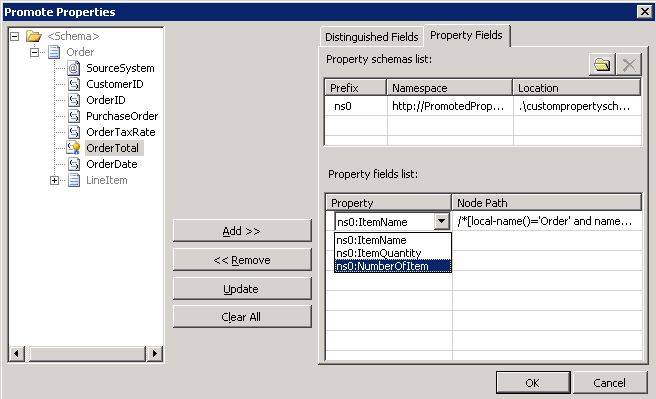
To manually promote a property, a property schema must be created with the elements that will hold the promoted property values. To create a property schema, you need to add a new item in your BizTalk solution, and chose Property Schema as the type of file (see Fig. 1.2). Once all the elements are created in the property schema, you associate the property schema with the message’s schema by right clicking on any node of the message schema and choose Show Promotions (see Fig. 1.3), then click on the Property Fields tab, click on the folder icon and finally select the property schema you just created (see Fig. 1.4). Note that it is actually possible to use more than 1 property schema per message. Anyhow, all promoted properties will end up being written in the message context and available for all BizTalk artifacts having access to message context.
Once the property schema is picked, you can start promoting message elements as promoted properties. To do so, click a message element and click on the add button, the Node Path column will display the XPath to the message element you are promoting and the Property column let you chose the promoted property that will contain the value of the message element at runtime (see Fig. 1.5).
An interesting side effect is that Manual Promotion let you have promoted properties with different names that the original message element name. This might be useful when a same property schema is used to hold promoted properties from different message types or when a message has different element with the same name.
Using Manual Promotion, it is also possible to promote message elements to promoted properties in the system property schemas shipped with BizTalk. To do so, just browse in the References sub-tree when picking the property schema (see Fig. 1.4).
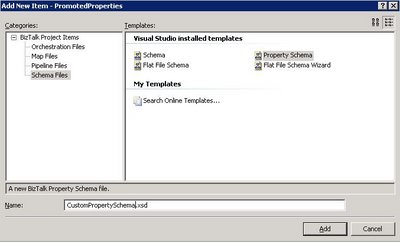 Fig. 1.2 Manually create a custom property schema
Fig. 1.2 Manually create a custom property schema
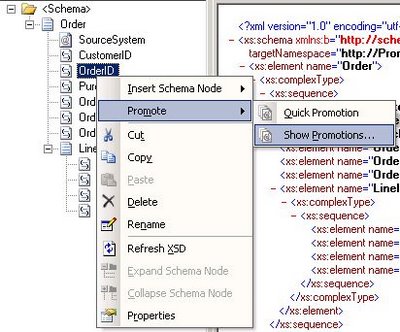 Fig. 1.3 Manual Promotion
Fig. 1.3 Manual Promotion
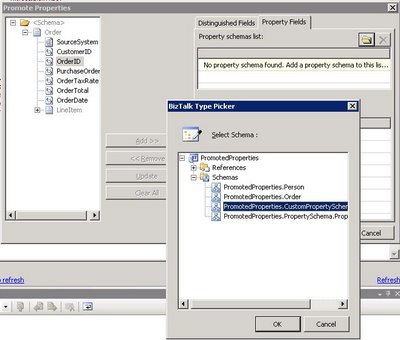 Fig. 1.4 Selecting a Property Schema
Fig. 1.4 Selecting a Property Schema
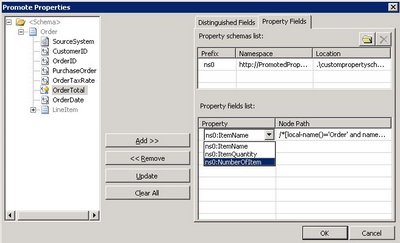 Fig. 1.5 Selecting the message element to promote and the promoted property that will contain the message element’s value.
Fig. 1.5 Selecting the message element to promote and the promoted property that will contain the message element’s value.
1.3 How to promote properties through the BizTalk API?
As I already said in a previous post, BizTalk Messaging Architecture, context properties are stored in a property bag, an object which implements the IBaseMessageContext interface. This interface contains 2 methods which take the same parameters (a property name, an XML namespace, and value for the property).
a. The Write() method is used to write the property value into the message context without actually promoting it. It can be used to write distinguished fields or to write transient values. Calling the Write() method is NOT promoting a property, it is writing a property.
b. The Promote() method is used to write the property value into the message context but also flags the property as promoted so that it is available for routing. This is the method that needs to be called to promote a property.
To promote a property through the API, element name and namespace passed as parameter of the Promote() method must be those of the property defined in the property schema. They are most easily accessed by referencing the property schema assembly and using the properties on the class created for the property.
Example of promoting a property through an API call (copied from the BizTalk 2006 MSDN documentation: Processing the Message):
//create an instance of the property to be promoted
SOAP.MethodName methodName = new SOAP.MethodName();
//call the promote method on the context using the property class for name and namespace
pInMsg.Context.Promote(methodName.Name.Name, methodName.Name.Namespace,
“theSOAPMethodName”);
As I mentioned before, it is possible to promote properties to the BizTalk system property schema using Manual Promotion in Visual Studio’s Schema Editor for BizTalk. It is possible to achieve the same programmatically and as for other promotion, the name and namespace passed in parameter of the Promote() method is the one of the promoted property in the property schema, the system property schema namespace in this case.
//BizTalk system properties namespace
private const string BTSSystemPropertiesNamespace = “http://schemas.microsoft.com/BizTalk/2003/system-properties”;
//Promote the MessageType property
string messageType = “http://” + “schemas.abc.com/BizTalk/” + “#” + “Request”;
message.Context.Promote(“MessageType”, BTSSystemPropertiesNamespace, messageType);
2. Distinguished fields
2.1. What are distinguished fields?
Distinguished fields are message elements that are written into the message context. They differ with promoted properties in 2 main aspects:
- They are not flagged as promoted in the message context and so are not available for routing by the Messaging Engine (adapters, pipeline…). Their typical use is instead for the orchestration engine.
- They are not defined using a property schema.
Distinguished Fields are WRITTEN in the message context by the pipeline when a message is received on a port. It is usually the job of the disassembler pipeline component such as the XML and Flat File disassembler but any custom pipeline component can also do it.
Distinguished fields are useful when a message element value needs to be accessed from an orchestration. Instead of having the orchestration engine search through the message to evaluate an XPath expression (which can be resource-intensive on a large message), a distinguished field can be used. Distinguished fields are populated in the message context when the message is first loaded. Consequently, each time the distinguished field needs to be accessed, the orchestration engine will directly read it from the message context (a property bag object) instead of searching for the original value in the message with XPath. Needless to say that retrieving a single value from a property bag object is much faster than evaluating an XPath expression.
Distinguished fields also offer IntelliSense in the orchestration expression editor which enhances code readability.
2.1 How to create a distinguished field?
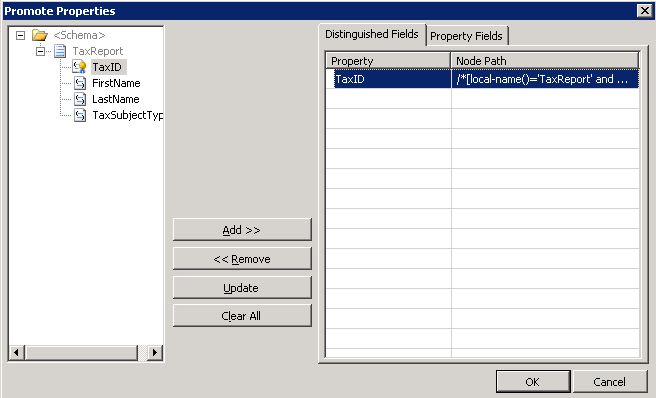
The main source of confusion between distinguished fields and promoted properties is that they are both created in Visual Studio’s Schema Editor through the Promote -> Show Promotions contextual menu option of a message schema’s element. Once the dialog box is open, make sure that you are on the Distinguished Field tab, select the message elements and click the Add>> and <<Remove buttons to add and remove distinguished fields (see Fig 2.1).
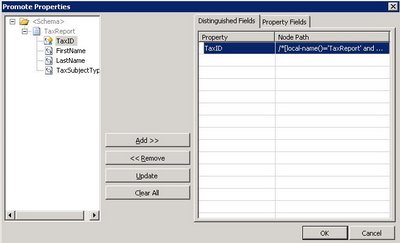 Fig 2.1 Creating a Distinguished Field.
Fig 2.1 Creating a Distinguished Field.
2.2 How to create a distinguished field through the BizTalk API.
Distinguished fields are written into the context using the Write() method on the IBaseMessageContext object. To be recognized as a distinguished field, the namespace of the property must be “http://schemas.microsoft.com/BizTalk/2003/btsDistinguishedFields”. Pipeline components delivered with BizTalk do not use those context properties. It is nevertheless possible to read/write distinguished field in the code of custom pipelines, as for any other context properties.
Example of writing a distinguished field through an API call (taken from the BizTalk 2006 MSDN documentation: Processing the Message).
//write a distinguished field to the context
pInMsg.Context.Write(“theDistinguishedProperty”,
“http://schemas.microsoft.com/BizTalk/2003/btsDistinguishedFields”,
“theDistinguishedValue”);
Would you use another namespace, it will result in writing a plain transient value in the property bag and won’t be recognized as a distinguished field by the orchestration engine.
//Write a transient value to the message context
message.Context.Write(“MyVariable”, “SomeNameSpace”, SomeData);
3. Considerations, similarities and differences between promoted properties and distinguished fields.
3.1 Performance considerations:
- Promoted properties are limited to 255 characters for routing performance reasons. Properties that are simply written in the context (such as distinguished fields) are not limited in size but large properties decrease performance.
- All Context properties (both Promoted and Distinguished Fields) are stored separately from the message in the Message Box Database. Consequently consuming more space in the BizTalk databases but more importantly incurs more load when persisting/reloading the message in/from the DB. Note that if tracking is turned on, Promoted Properties are also stored in the Tracking database.
- Distinguished Fields cost less than Promoted Properties in terms of performance. Both Promoted and Distinguished Fields require the same overhead of writing their values to the context Field bag in the Message Box database, but Promoted Fields have the additional overhead of being written in BOTH to the Message Box context tables AND the subscription tables. Distinguished fields are not stored in the subscription table as they do not participate in routing.
Promoted Fields have an impact every time a message is written in the Message Box because each Promoted Property that exists must be evaluated in a massive T-SQL union statement that builds the list of matching activation subscriptions. In short, the more Promoted Fields you have the more costly the subscription process is.
3.2 Other considerations
- Both promoted properties and distinguished fields are populated when a Pipeline Disassembler Component parses a message and either Promotes or Writes the value to the message’s context.
- Empty pipelines such as the Pass-through pipeline do not promote or write anything in the message context as it lacks a disassembler component.
- Writing a value into the context with the same name and namespace that were used previously to promote a property causes that property to no longer be promoted. The write essentially overwrites the promotion.
- Writing a property in the context having a null value deletes the context property altogether because null-valued properties are not permitted.
3.3 Distinguished and Property Fields Difference Summary.
- Promoted Fields should be used for routing, correlation and/or tracking.
- Distinguished fields should be used when a particular message element is commonly manipulated in one or more orchestration.
Here is a table outlining the main differences between both types of fields:
| Promoted Fields (aka Promoted Properties) |
Distinguished Fields |
Used for routing (subscription mechanism)
IsPromoted = true |
Do not participate in routing
IsPromoted = false |
| Used for tracking |
Not used for tracking |
| Restricted to 255 characters |
No size limitation |
| Available for use in orchestrations |
Available for use in orchestrations |
| Require property schema |
Do not require property schema |
| Used by standard pipeline components |
Accessible only by custom pipeline component which would explicitly access them |
4. References.
MSDN – The BizTalk Server Message
MSDN – Processing the Message
MSDN – About BizTalk Message Context Properties
Neudesic’s blog – Distinguished fields myths